Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём некорректно. Вам необходимо обновить браузер или попробовать использовать другой.
Например, я сейчас решил поиграться со своими настройками индексации и проверяю такой шаблон подачи, интересно, что выдаст. В этот раз уделил особое внимание к вредным ботам и оптимизации обработки и удалением лишних дублей там, где это не нужно.
Шаблон дефолтный, можете себе поставить, если хотите, лишнее от плагинов убрал и поправил те места, где правил для себя.
Сразу предупреждаю, у меня пока XF 2.2, но думаю хорошо и на 2.3 будет.
Этот вариант ничем не хуже того, что писал ранее тут. Но отличие в том, что он чище, оптимизирован и расширен на блок вредных ботов. Будет ли лучше, не знаю, сам проверяю, но отпишусь, как будут интересные результаты или наоборот.
Прописывать Crawl-delay: лишь пробую, мол указывается задержка некоторая, хз будет ли толк, проверяю. Да и гугл вроде как их особо не учитывает, а вот другие могут.
В общем, уже спустя некоторое время, объём обхода вырос в разы, если верить статистике с 20 ноября по 1 декабря:
Новый шаблон работает лучше, ухудшение на тему дублей или ошибок так же не выдавало. По индексации сложно сказать, на выдаче некоторые страницы были на 4-7 страницах, сейчас на 1-3 страницах выводится, что выводилось намного дальше. Так что определенно успех есть. А вот в Google Console особо изменений не увидел, разве что ругался на запреты на чтение пользователей и постов, хотя в запретах общих не стоит, тут непонятки, как он вообще проверяет, но разве что проверенные страницы к публикации стали чуть больше, в этом плане стало лучше.
Так что по своим наблюдениями могу сказать, что новый шаблон работает отлично. По поводу прописывания .htaccess ничего не могу сказать, есть ли в этом сильная необходимость, пока не вижу у себя необходимости. Шаблоном можно пользоваться по robots точно без проблем, разве что дорабатывать по своим плагинам, если кто где выводит страницы.
Мне вот интересно, боты вообще стали игнорить общие правила? Стоило с яндекса убрать учёт тегов и добавить в общую, они начали в яндексе индексироваться...
Видимо яндекс на столько исключительные, то работают тока "по своим" правилам. Вернул теги на место, посмотрим вылезет ли ещё что...
Ещё и тут вылезло из-за них:
Занятные данные получаю.
Стоило вернуть теги в яндекс разметку и сразу начал чистить. Так что, могу смело заявить, если что вы прописываете под User-agent: Yandex, то яндекс обязательно учтёт. На общие запреты вне этой пометки ему будет плевать. Что тут сказать, яндекс подсчитали себя особенными.
У меня вопрос, а как вообще можно у себя обозначить те или иные страница, как атрибут rel="canonical"? Я вот понять не могу. Может кто наглядный пример показать, как на XF у себя подобное реализовать?
А вот что стало по обходам, начиная от 20 ноября по 16 декабря.
Всё же изменения дали свои плоды на доп.обходы и даже наконец префиксы и страницы начал учитывать, если выше посмотрите под спойлером (хотя странно, по префиксам нет, они в яндекс ветке прописаны, а вот страницы тока в общей ветке... загадка 0_о). Всё же мой шаблон работает как надо. Эксперимент прошёл успешно, заодно узнали интересный нюанс о яндексе.
Что касается гугла, то разницы почти не увидел, что до, что после т.к. запретов то почти и не было в общей ветке, так что и не удивительно.
Учитывая, что на 2.2 моя версия прижилась очень отлично, никаких нареканий нет, если кто сидит ещё на этой версии, то смело можете ставить - НАЙТИ ТУТ. Смело можно и на 2.3 использовать, вреда никакого, разве что добавить следует пару пунктов на блок.
А теперь об интересном, я наконец обновился до 2.3.10 и конечно, после сразу заметил изменения и необходимость прописать более глубже настройки.
Теперь начинаем новый эксперимент с 1 марта:(Тут готовый шаблон для дефолта, можете спокойно использовать, если считаете нужным)
Если что, настройки и для XF 2.2 подойдут, даже если у вас нет того, что указано для 2.3, на будущее обновление уже не нужно будет заморачиваться.
/posts/ в моём случае не блокируется весь, а только повторяющие на нём страницы. К тому же включен IndexNow, потому блокировать не рекомендуется на 2.3 при его включении. Не знаю будет ли толк от IndexNow, но посмотрим. Если у вас отключен IndexNow (Или его нет на XF 2.2), то в robots рекомендуется добавить запрет так:
Код:
Disallow: /posts/*/
Disallow: /*post-
Особое внимание стоит отдать /misc/cookies и /misc/style-variation (XF 2.2 вариантов стиля нет). На них самые активные запросы. Блочить обязательно. Если у вас в поиске используются tags, то конечно открываем. Остальное, на свои потребности уже смотрим. И местами featured проходит (На XF 2.2 можно открыть, будет полезен), блокируйте на усмотрение, но учитывая, что на нём нет мета описания, то лучше блочить. Запомните главное правило, если на нужной странице у вас в коде не прописывается meta заголовок и описание, то 100% будете ловить ошибки, по коду страницы проверяйте обязательно. Особенно на это чувстителен яндекс. На гугл можете забить болт, он всё хватает и если вы акцентрируетесь на него, то по нему и смотрите. Но для него и общих правил будет уже за глаза.
И конечно, если вы пользуетесь рекламой Ads гугла, то лучше убрать из правила запрет на Mediapartners-Google и adsbot-google.
Список ботов расширился и стоят полные запреты или временные интервалы, учитывая, что некоторая часть будет игнорировать правило, но в случае агрессивных, блочим на уровне сервера, в остальном некоторую часть отвадит и снизит лишнюю нагрузку на обработку ботов.
Disallow: /*/reactions - # техническая страница реакций, индексировать не нужно, но будет хватать дубли с ним. У нас уже оно стоит.
Disallow: /*/*/reactions # тоже самое, но глубже по структуре. Необязательно, но и не лишне.
Disallow: /*?prefix_id* # кто работает с префиксами, будет важно добавить тоже, иначе ждите дубли.
Disallow: /*?content_type= # так же требует запретить, если он фигурирует ещё где-то, помимо featured (рекомендуемые).
Если яндекс будет игнорить, то добавить в Clean-param: как content_type. Помимо него, в whats-new есть подобные переменные на обработку и все они выводятся из-за "фильтров", если будет прецендент на это, то вы знаете где их искать и по пути прописать, что убрать.
Рекомендуется так же добавить в общий и блок яндекса:
Код:
Disallow: /members/ # Убираем индексацию профилей пользователя в общем блоке. На яндекс уже есть. Чтобы не разводить мусор.
Disallow: /forums/*/page-* # Убираем пагинацию страниц с форумов
Disallow: /threads/*/page-* # Убираем пагинацию страниц с тем
По поводу пагинации, то это речь про дубли, которые вы получаете, например с page-1, page-2 и т.д. это правило убирает индексацию этих страниц, вам оно и не нужно, вам важно индексировать основную. Если нужно, можете на общем блоке не указывать на members, но на яндекс обязательно.
Если у вас даже прописан "canonical" на страницу, но не настроено правило индексации на пагинацию, то вы всё равно будете ловить дубли. Пропишите эти правила в общий блок и яндекса.
Я сужу по данным к своему вебмастеру яндекса и пробиваю дыры, что ещё лишнее он пытается индексировать. Следовать ли этим рекомендацией, ваш выбор. Хотите мусорной выдачи на свой домен, то можете ничего не прописывать и выбрать свой путь.
Чтобы ускорить чистку и проверку, то не забываем удалять лишний мусор: (показываю где)
Как понять, что можно удалить?
Нам понадобятся 2 раздела: Индексирование - Заголовки и описания и Страницы в поиске. И любая нейронка для помощи в анализе (Только не Алиса, побойтесь бога), я пользуюсь DeepSeek (он порой тоже несет ахинею, но в нём важно правильно задавать запрос).
1) Заходим на Заголовки и описания и видим это:
Отсюда нам нужно нажать на XLS во вкладке title и description. В каждой вкладкой, свой XLS т.е. вам нужно 2 файла!
2) Заходим на Страницы в поиске, мотаем список в самый низ и видим это (на моём примере можно увидеть, что members индексируется, что не должно, хотя в блоке яндекс был прописан, но на общем нет, так что в своём случае добавил в основной блок запрет):
И тут жмём XLS. Вкладка изначально на "Последние изменения" у вас так и остается, смотреть другие нам не нужно, мы судим именно по последним обходам. Если надо, сделайте по всем, тоже не лишне.
После этого, загружаем все эти Excel файлы в вашу нейронку и не забудьте выгрузить так же сам robots.txt и напишите, примерно такой запрос "Проанализуруй файлы, выдай URL адреса дублей и прямые обходы. Укажи список для копирования, какие URL нужно удалить и укажи на ошибки в robots.txt". После этого он вам даст список, который вставите на удаление, что писал выше. Это ускорит процесс чистки от мусора.
Нейронкой неплохо и проверять сам robots, может дать подсказки, но верить всему тоже не стоит, надо и самому проверять т.к. он не даст вам точного ответа, а что лучше прописать.
Хочешь хорошего SEO, включай голову. Таков путь.
P.S. Тут как бы не идут уже споры на блокировку гугла, так что на его учёт даже не смотрю. Можно конечно на общий блок вообще всё открыть, гугл с удовольствием всё это схавает, как и другие, но в его консоли анализа вы будете ловить тонны ошибок на те же проблемы, что и в яндексе. Выбор за вами.
Если тесты пройдут гладко, то можно специально для XF 2.3 сделать русурс справку. Но в остальном, всё думаю будет норм.
Тема настройки robots.txt думаю больная у каждого и пора бы уже давно поставить жирную точку.
Естественно, не забываем, что мы доводим до приличного уровня дефолтный набор, если у вас плагины, типа NEWS, AMS, XenPortal, галереи, магазины и прочее, то их так же нужно будет учитывать, а это отдельный анализ индивидуально у каждого.
Нейронкой неплохо и проверять сам robots, может дать подсказки, но верить всему тоже не стоит, надо и самому проверять т.к. он не даст вам точного ответа, а что лучше прописать.
Скорее не совсем в тему будет, но тоже про индексацию. Все больше поисковики (Не яндекс, он и тут болен прости господи) используют ИИ при поиске и стандартная индексация все больше улетает в небытие (что кажется нереальным), поскольку новомодные тренды и в целом любые нейронки, которые выдают ответ в самом поисковике после запроса (тот же гугл) основываются на файле llms.txt. С ним тесты не пробовали проводить? Как пример (не реклама, упаси господь от подобного продукта и услуги, есть у
У Вас недостаточно прав для просмотра ссылок.
Вход или Регистрация
). Подобную реализацию у проектов видел некоторых, отзываются позитивно о работоспособности.
(тот же гугл) основываются на файле llms.txt. С ним тесты не пробовали проводить? Как пример (не реклама, упаси господь от подобного продукта и услуги, есть у
У Вас недостаточно прав для просмотра ссылок.
Вход или Регистрация
). Подобную реализацию у проектов видел некоторых, отзываются позитивно о работоспособности.
Первый раз слышу, можно поподробней? Гугл знаю, всё больше полагаются на ИИ и не так скоро обычная индексация умрёт с ним. Но основна цель тут не только привести в порядок выдачу в поиске, но и снизить лишнюю нагрузку ботов на сервер, конечно ничто не мешает на самом сервере это прописать, но это актуально лишь с более агрессивными. А по поводу выдачи ИИ не знаю, по крайне мере информации не слышал, что появились новые способы индексации на их счёт.
ИИ-пузырь в действии: сейчас огромная аудитория использует нейронки вроде ChatGPT, Gemini или DeepSeek в качестве полноценной замены классическому поиску. Судя по всему, современные модели при сборе данных всё чаще игнорируют директивы robots.txt, предпочитая напрямую продираться сквозь "шум" — рекламные баннеры, скрипты и прочий визуальный мусор.
Чтобы оптимизировать этот процесс и повысить шансы сайта оказаться в списке источников, сейчас активно внедряют llms.txt. Это Markdown-файл в корневом каталоге, который решает ту же задачу, что и его предшественник, но на другом уровне: он предоставляет нейросети готовую, структурированную выжимку самого полезного контента. Модель не тратит ресурсы на парсинг мусора, за счет чего семантическая ценность ресурса в глазах ИИ кратно возрастает, а вероятность корректного цитирования становится выше.
Коллеги уже реализовали аддон, который через периодическую джобу сканирует контент форума и автоматически собирает актуальный llms.txt. Если проводить аналогию, то robots.txt — это суровый охранник на КПП, который просто проверяет пропуска, а llms.txt — это персональный экскурсовод, который за руку ведет модель к самой важной и полезной информации.
upd: дополню, что есть немного более информативные постики на других площадках (не реклама):
У Вас недостаточно прав для просмотра ссылок.
Вход или Регистрация
Коллеги уже реализовали аддон, который через периодическую джобу сканирует контент форума и автоматически собирает актуальный llms.txt. Если проводить аналогию, то robots.txt — это суровый охранник на КПП, который просто проверяет пропуска, а llms.txt — это персональный экскурсовод, который за руку ведет модель к самой важной и полезной информации.
Как почитал, ни одна из крупных компаний этот вариант обработки не использует, по крайне мере официально не было заявлений. В остальном, как понимаю, он служит больше дополнением и проводником того, какой контент наиболее важно показывать, но при этом он вынуждает раскрывать полную структуру этого контента по ссылкам, вплоть до прописания мета заголовка и описания вручную. Иначе говоря, этот файл помогает ИИ струкуризовать важные для нас URL для выдачи в поиске, но как это будет эффективно, сложно сказать, мало информации.
Только, мне не совсем понятно, зачем нужен плагин для этого? Разве что, он будет формировать готовую форму для создания и выдачи всего или определенного контента на XF, я вижу пользу в плагине тока в этом, чем делать вручную. Изучу надосуге этот вопрос более детально.
Разве что, он будет формировать готовую форму для создания и выдачи всего или определенного контента на XF, я вижу пользу в плагине тока в этом, чем делать вручную
Сократить ручной труд, но там тоже потратили что-то типа 450-600$ на разработку, мне детали не раскрывали, сказали что просто позволяет быстрее все собирать в файл, чем руками тратить по несколько часов. Это все вот новомодная мишура, было интересно просто, в курсе ли вы про это, да и подкинуть как идейку, на подумать.
Сократить ручной труд, но там тоже потратили что-то типа 450-600$ на разработку, мне детали не раскрывали, сказали что просто позволяет быстрее все собирать в файл, чем руками тратить по несколько часов. Это все вот новомодная мишура, было интересно просто, в курсе ли вы про это, да и подкинуть как идейку, на подумать.
Есть хоть уже рабочий шаблон подачи в таком файле? Потому что вызывает лишь вопросы актуальность этой задумки. Одно дело помочь продвигать в поиске, другое платные рекламные гиганты этого просто не дадут, яндекс точно.













 (Тут готовый шаблон для дефолта, можете спокойно использовать, если считаете нужным)
(Тут готовый шаблон для дефолта, можете спокойно использовать, если считаете нужным)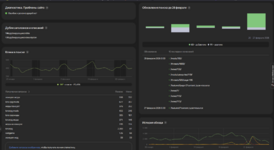

 ), я пользуюсь DeepSeek (он порой тоже несет ахинею, но в нём важно правильно задавать запрос).
), я пользуюсь DeepSeek (он порой тоже несет ахинею, но в нём важно правильно задавать запрос).




